Interaktives Data Mining und Prognose (Predictive Analytics)
Data Mining und Prognose erforderte bisher tiefergehendes Experten- und Tool-Wissen. Viele im Markt befindliche Systeme sind für sehr große Datenmengen nicht geeignet. Synop Analyzer macht Data Mining so einfach wie nie zuvor. Interaktiv, ohne Programmierung, auf fast jeder Datenmenge und mit hohem Automatismus werden Scoring-Modelle aus Daten in wenigen Minuten erstellt. Mittels diverser Formate und Interface können operative Systeme damit gesteuert werden.
Regressions-Training und Prognose
Die lineare Regression wird für die Vorhersage von Werten aus numerischen Daten und die logistische Regression für die Vorhersage von zweiwertigen Informationen eingesetzt.
Typische Einsatzfälle
- Ausfallraten bei Krediten scoren
- Score-Karten Erstellung
- Teilnehmer für Kampagnen scoren
- Affinitäts-Score
- Beschwerden-Scoring
- Kündiger-Score
Naive-Bayes Training und -Vorhersage (Scoring)
Ein Naive-Bayes-Klassifikationsmodell ist ein Data Mining Modell, das den (unbekannten) Wert eines bestimmten Datenmerkmals, das sogenannte Zielfeld, aus den Werten mehrerer anderer Datenfelder, der sogenannten Prädiktorfelder, vorhersagt.
Die Vorhersage-Formel wird während eines sogenannten Trainings auf Trainingsdaten ermittelt, bei denen
sowohl das Zielfeld als auch die Prädiktorfelder mit Werten gefüllt sind. Das Klassifikationsmodell kann später auf neue Daten angewendet werden, in denen die Zielfeldwerte fehlen. Auf diese Weise kann man Zielfeldwerte vorhersagen. Die spaltenorientierte In-Memory-Datenhaltung des Synop Analyzer ermöglicht es, dass Naive-Bayes-Modelle selbst auf extrem große Datensätze äußerst schnell trainiert und anwendbar sind – meist sogar annähernd in Echtzeit.
Analyse und Prognose von Zeitreihen
Daten mit Zeitstempel können mit dem Modul Zeitreihenreihenanalyse auf Trends und zyklische Muster hin analysieren. Die Software kann Prognosen für die zukünftige Entwicklung unter verschiedenen Annahmen bezügl. Trenderhaltung und Fortwirken vergangener Ereignisse berechnen. Umsätze, Kosten, Verkaufszahlen und vieles mehr lassen sich vorhersagen und somit die gekoppelten Maßnahmen besser steuern.
Self Organization Maps (SOM)
SOM, basierend auf dem Kohonen-Verfahren, kann zur Segmentierung (Clustering) und zur Vorhersage (Scoring) eingesetzt. Verschiedene neuronale und nicht-neuronale Data-Mining-Verfahren ermöglichen die Segmentierung von Daten und das Berechnen von Vorhersagen und ‚Score‘-Werten.
Typische Anwendungen:
- Fehlerausfall-Wahrscheinlichkeiten
- Kundensegmentierung
- Zahlungsausfallrisiken
- Zu erwartende Deckungsbeiträge
- Kündigungsrisiken
- Zukünftiges Kundenpotenzial
Data Mining Knowhow
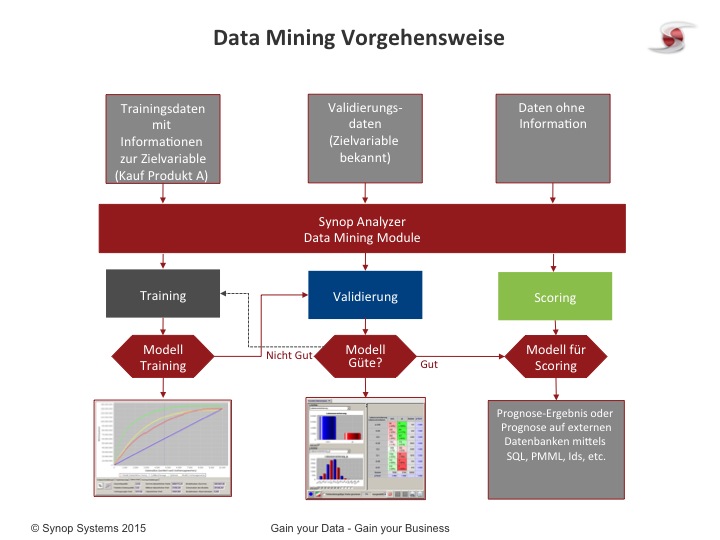
Welche Prozesse sind für eine Prognose notwendig?